 I
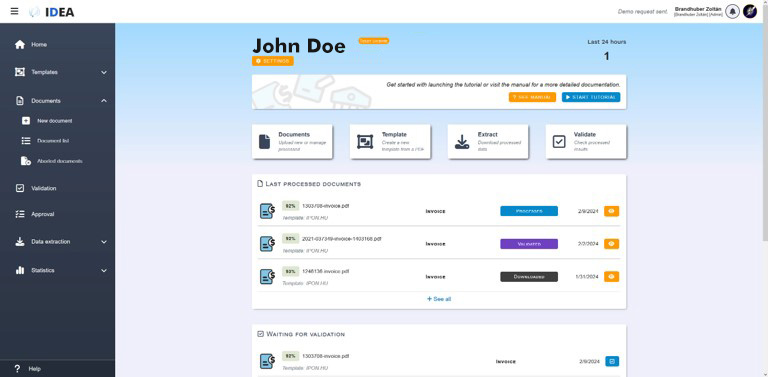
IA rendszer célja a szkennelt vagy elektronikus formában beérkezett dokumentumok (pdf állományok vagy képfájlok) feldolgozása, felismerése és az értékes információk kinyerése; strukturált formába alakítása.
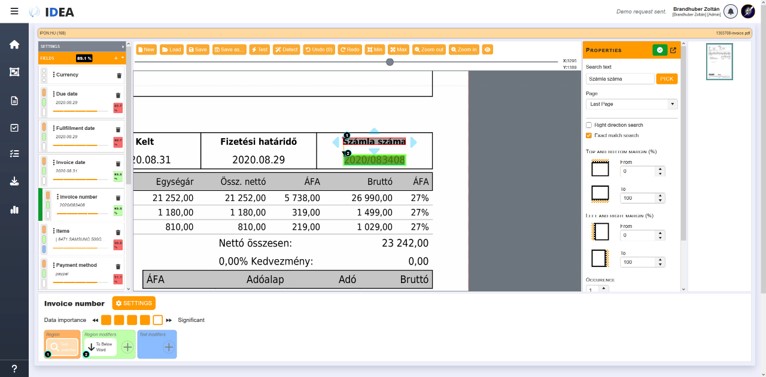
Hasonló elven nem csak egyes mezők adatai, de akár egész táblázatok is visszaalakíthatók táblázatos formába. Ehhez a rendszer megkeresi a táblázat fejlécét, felbontja azt oszlopokra, majd sorokat próbál elhatárolni a fejléc alatti régióban egészen addig, amíg a táblázat végét jelző részekhez nem ér. Folytonos, több oldalon is ismétlődő táblázatok esetén is képes továbbmenni, azaz a felismerés nem akad meg az első oldalon.
Az így felismert elemek - metadat mezők, táblázatos adatsorok - ezután validációs szabályok szerinti ellenőrzésre kerülnek. Minden egyes adathoz szintaktikai és egyéb szabályokat rendelhetünk, megmondva a felismerésre kerülő adat típusát, lehetséges adattartalmait (például zárt értékkészletek esetén) vagy éppen hosszát.
A beérkező dokumentumtípusok azonosítását szintén egy mélytanuló neurális hálózati rendszer végzi, amely elemzi a dokumentum képét és adattartalmát. A korábban rendelkezésre bocsátott tanulókészletek szerint meghatározza az alkalmazásra kerülő szabályokat és megpróbálja kinyerni az adatokat. Amennyiben a dokumentum még ismeretlen, a rendszer megpróbál a korábbi, általa már ismert szabályok szerint a legvalószínűbb megoldást felkínálni és ezek alapján felépíteni az új szabálykészletet. Ahogy egy adott dokumentumtípusból újabb példányok érkeznek, a rendszer fokozatosan megtanulja ezek kinézetét és a felismerési eredményeket visszatáplálva javítja a felismerést.
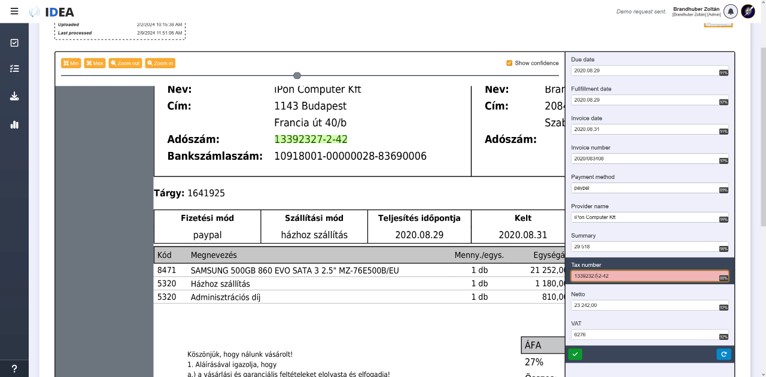
Ha egy dokumentumtípusra már létezik felismerési mintázatunk, a rendszer azt felismeri a beérkező dokumentumok között, és alkalmazza rájuk a feldolgozási szabályokat. A szabályok mentén kinyeri az információt, amelyet számítógépes feldolgozásra kész JSON vagy XML formátumba konvertál, és így ad át a társrendszerei részére.